The Arabic gap: why most voice AI fails in MENA markets

Voice AI has crossed a threshold of perceived reliability, capability and cost. It’s now being rapidly rolled out to cover transcription, synthetic voice, conversational assistants and voice agents, all at near-human speed and capability.
The market has noticed. Globally, the voice recognition market hit $18.39 billion in 2025, projected to reach $61.71 billion by 2031, powered in large part by the fast-growing category of voice agents, forecast to add $10.96 billion between 2024 and 2029 alone.
The MENA region is very much part of this growth story. Investment is flowing in from both local players and international companies, and voice AI is already at work across the region: cutting documentation time in hospitals, handling millions of contact centre calls, helping local KFC drive-throughs to go conversational.
In a 2025 survey of GCC organisations, AI adoption had risen from 62 to 84 per cent, yet only 31 per cent reported scaled deployment. In voice AI specifically, that gap is most often a language problem.
The glaringly obvious problem
The overwhelming majority of voice AI products are simply not built for this region. In a recent survey by Researchscape International, 92 per cent of respondents in the UAE said they would prefer a smart or AI assistant specifically designed for the Middle East.
That makes sense, because most voice AI products share the same set of original sins: built as English models first, trained on synthetic data, tested in ideal lab conditions. This approach can’t keep up with the reality of a noisy Gulf contact centre or a bustling Cairo hospital ward.
Most voice AI products are monolingual. And monolingual is no use for a language that is not monolithic.
One model to hold them both
Most of the market is still building this way. And while my team and I at Speechmatics have been building differently for 15 years, we were still falling short for the enterprise use-cases in the region.
That is what pushed us to build the world‘s first medical Arabic-English bilingual model. One model, both languages, trained on real voices from across the region.
On recent benchmarks, it is performing 35 per cent above the next-best model.
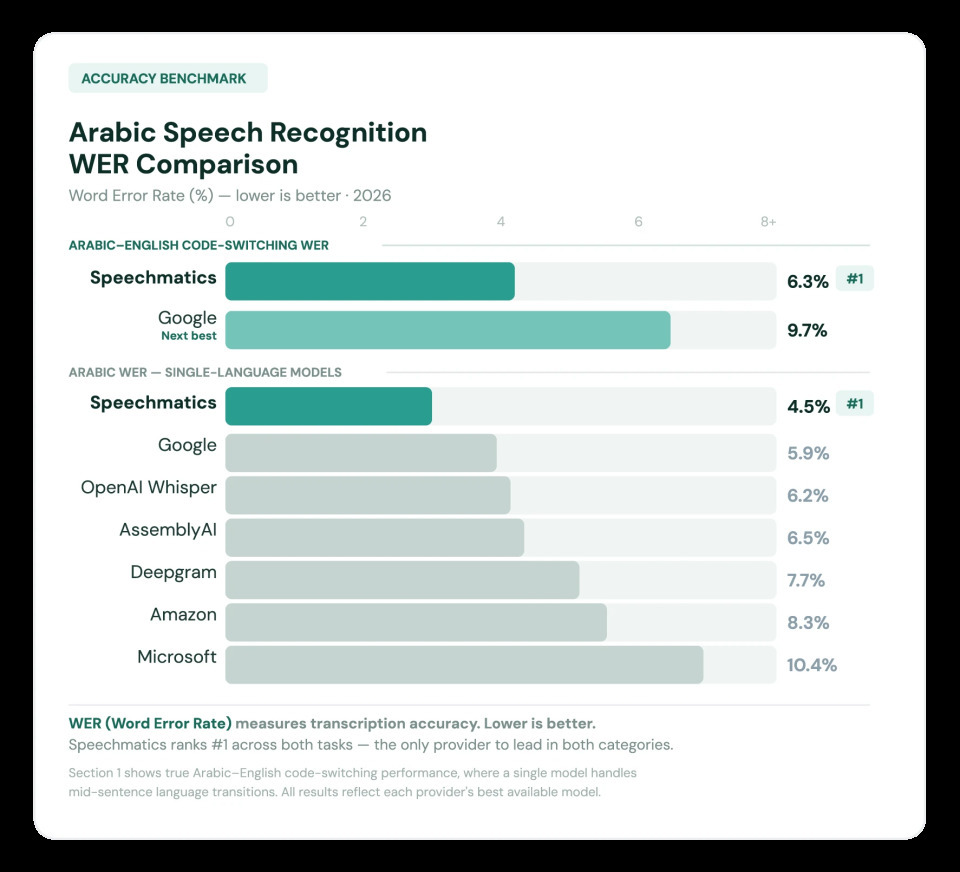
Here is why I know this model will make a difference in Arabic-speaking countries.
A language that does not behave like other languages
Arabic is not a single language in any practical sense. Gulf, Egyptian, Levantine and Maghrebi dialects carry distinct vocabulary, phonology and rhythm.
Different people will pronounce the same word differently. The variation is comparable to a thick Boston accent and a deep Mississippi drawl.
I‘m Egyptian. My accent carries differently to a Gulf speaker’s, and both of us carry differently to someone from Tunis or Beirut. A model trained primarily on broadcast Modern Standard Arabic will struggle with many real conversations.
We made sure we had examples from different dialects and dialect-specific training data precisely because enterprises need products and services that travel across borders.
Code-switching: the wall no one sees coming
In most Arabic-speaking countries, people often switch between English and their dialect, particularly between formal speech and conversational speech. It is the default register for educated professionals across the region, such as a doctor naming a drug in English or a finance officer mixing both in a single sentence.
The Gulf also has one of the highest concentrations of expat communities in the world, where Arabic and English are the working languages. If someone switches mid-sentence, running two models in parallel does not fix it. If you run two models, one is going to think this is English and one‘s going to think it’s Arabic, and to combine them they won’t know which one to listen to.
For optimum accuracy and speed, you need a single model that knows both languages simultaneously and can differentiate between the words as they are being spoken.
Specialised models: when errors stop being typos
In regulated sectors, a transcription error is a potential liability. Nowhere more so than medical transcription, where a weak model that drops a drug name puts that error straight into the patient record, creating more work for already stretched doctors.
A dedicated domain model does not just reduce those errors. It allows us to achieve even higher accuracy in real settings, where vocabulary is specialised and code-switching is constant.
As voice agents move into clinical and regulated environments, the tolerance for that gap moves toward zero. That is why we built a dedicated Arabic-English medical model trained on clinical vocabulary and real code-switching.
You can see our new medical model tested in the real world by a retired Egyptian anaesthetist (also my father!), below.
Where the model runs matters as much as how it performs
Enterprises across the region are asking whose infrastructure their sensitive data runs on. Saudi Arabia’s Personal Data Protection Law came into full enforcement in September 2024, and the UAE’s Federal Data Protection Law has been in force since January 2022.
Both have concrete implications for where voice data is processed and stored, and cross-border processing triggers obligations many vendors cannot meet.
Beyond compliance, enterprises across the region are asking whose infrastructure their sensitive data runs on. The current geopolitical climate has made that question harder to ignore, and deployments here reflect it: on-prem and on-device, built around sovereignty from the outset.
The infrastructure is arriving. The linguistics need to keep up.
All these things are tangible improvements that will really make a difference: in hospital systems, in government service fronts, in the contact centres handling tens of millions of interactions a year across the region.
But the models have to work for the people using them. The gap is measurable, but it is closing.
Read more about Arabic transcription on speechmatics.com
By Yahia Abaza, Senior Product Manager, Speechmatics

Business Reporter Team
You may also like






Most Viewed
Winston House, 3rd Floor, Units 306-309, 2-4 Dollis Park, London, N3 1HF
23-29 Hendon Lane, London, N3 1RT
020 8349 4363
© 2025, Lyonsdown Limited. Business Reporter® is a registered trademark of Lyonsdown Ltd. VAT registration number: 830519543